Whisper入门学习资料 - 强大的多语言语音识别模型
459 2024-12-17 00:00:00Whisper简介
Whisper是OpenAI开发的通用语音识别模型,具有以下特点:
支持多语言语音识别、语音翻译和语言识别在大规模、多样化的音频数据集上训练采用Transformer序列到序列模型架构开源代码和模型权重,使用MIT许可证发布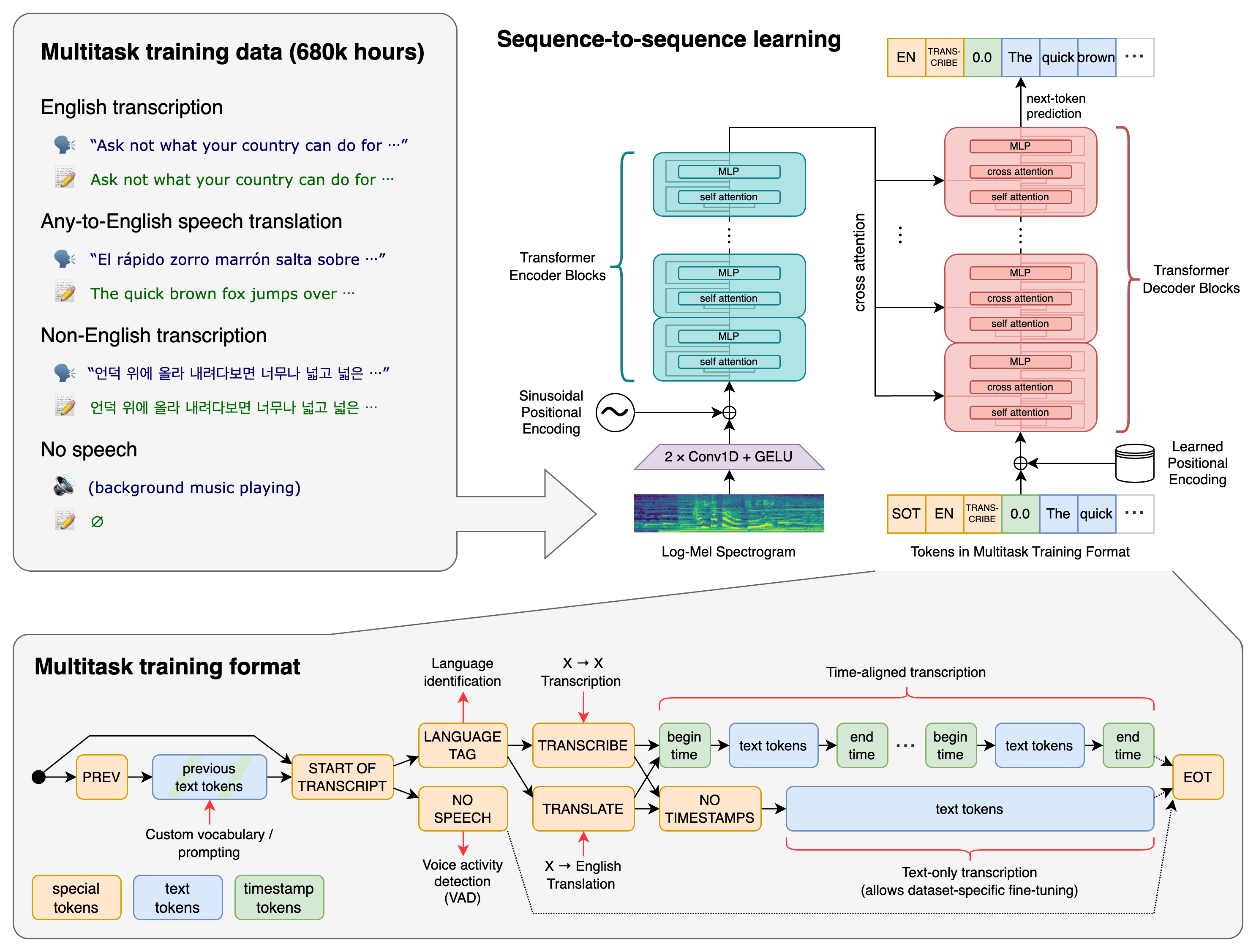
安装和使用
安装
可以通过pip安装Whisper:
pip install -U openai-whisper或者从GitHub安装最新版本:
pip install git+https://github.com/openai/whisper.git命令行使用
使用medium模型转录音频文件:
whisper audio.mp3 --model medium指定语言和翻译任务:
whisper japanese.wav --language Japanese --task translatePython API使用
import whispermodel = whisper.load_model("base")result = model.transcribe("audio.mp3")print(result["text"])可用模型
Whisper提供了5种不同大小的模型,适用于不同的场景:
模型参数量内存需求相对速度tiny39M~1GB~32xbase74M~1GB~16xsmall244M~2GB~6xmedium769M~5GB~2xlarge1550M~10GB1x其中tiny、base、small和medium模型还提供英语专用版本。
更多资源
GitHub仓库Whisper博客介绍论文Colab示例模型卡片Whisper是一个功能强大、易于使用的语音识别工具,希望这些资源能帮助你快速上手并充分利用它的能力。如果你在使用过程中有任何问题,欢迎查阅官方文档或在GitHub上提问。






热门资讯
-

- Botpress学习资料汇总 - 开源对话式AI平台
- 1608 2024-12-16 16:31:42
-

- BibiGPT-v1: 革命性的AI音视频内容一键总结工具
- 1964 2024-12-19 05:49:31
-

- Ethora: 开源 Web3 社交平台引擎
- 1603 2025-01-06 17:56:26
-

- DouZero: 基于自我对弈深度强化学习的斗地主AI系统
- 753 2024-12-19 02:10:32
-

- 开源数据工程项目精选:打造现代数据基础架构
- 1637 2025-01-06 16:16:54
-

- AI也能刷短视频了?!清华大学最新发布短视频理解模型,含图像文本音频多模态理解
- 1143 2024-12-31 16:07:01
-

- Diffree:最新模型实现文字指令修改图片!!这下修图变得更简单了
- 1477 2024-12-31 16:27:01
-

- 北大团队最新发布全景3D技术!只需一张图片和一段话就能生成全景3D场景
- 804 2024-12-31 16:46:55
-
- React Agent 学习资料汇总 - 开源 React.js 自主 LLM 代理
- 1201 2025-01-03 17:08:43
-

- Mojo编程语言学习资料汇总 - 兼具Python语法和系统级性能的AI编程语言
- 1624 2025-01-06 14:37:19










相关常用工具
查看更多- 1 cheetah 410
- 2 SUPIR 956
- 3 Conference-Acceptance-Rate 197
- 4 DouZero 1287
- 5 GodMode 1938
- 6 MeloTTS 941
- 7 codefuse 1945
- 8 腾讯云 AI 代码助手 1438
- 9 CodeGeeX 1460