SenseVoice学习资料汇总 - 多语种语音理解模型
1453 2024-12-17 00:00:00SenseVoice简介
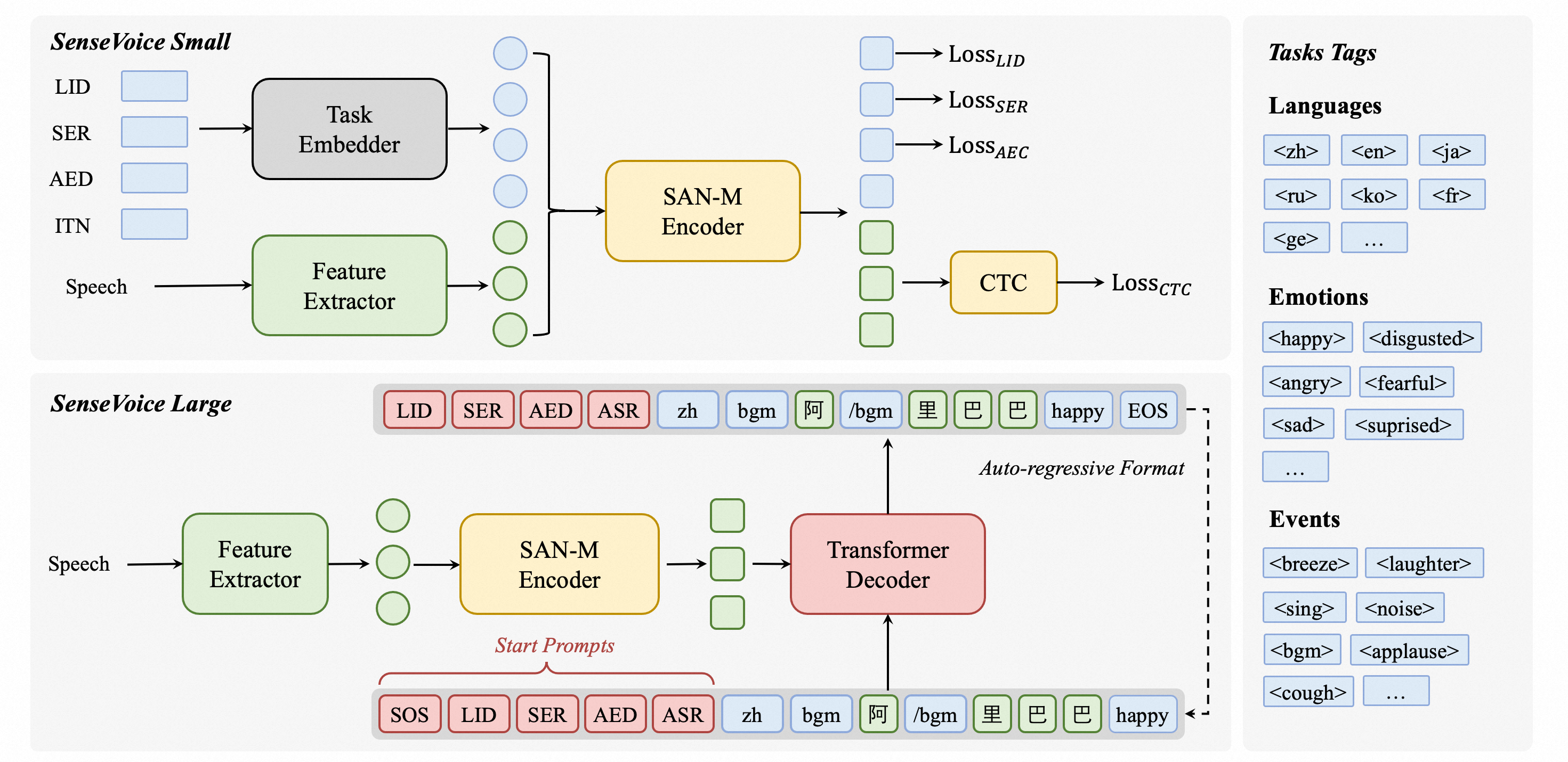
SenseVoice是一个多功能的语音理解基础模型,具有以下主要特点:
多语种语音识别:训练数据超过40万小时,支持50多种语言,识别性能超过Whisper模型。丰富的转写功能:具有出色的情感识别能力,支持检测背景音乐、掌声、笑声、哭声等多种人机交互事件。高效推理:SenseVoice-Small模型采用非自回归端到端框架,推理延迟极低,处理10秒音频仅需70毫秒,比Whisper-Large快15倍。便捷微调:提供便捷的微调脚本和策略,方便用户解决长尾样本问题。服务部署:提供服务部署流程,支持多并发请求,客户端语言包括Python、C++、HTML、Java、C#等。学习资源
代码仓库
GitHub: https://github.com/FunAudioLLM/SenseVoice模型下载
ModelScope: https://www.modelscope.cn/models/iic/SenseVoiceSmallHugging Face: https://huggingface.co/FunAudioLLM/SenseVoiceSmall在线Demo
ModelScope: https://www.modelscope.cn/studios/iic/SenseVoiceHugging Face: https://huggingface.co/spaces/FunAudioLLM/SenseVoice相关工具包
FunASR: https://github.com/modelscope/FunASRfunasr-onnx: https://pypi.org/project/funasr-onnx/funasr-torch: https://pypi.org/project/funasr-torch/使用教程
详细的使用教程可以参考GitHub仓库中的README文档。其中包括:
模型推理模型导出(ONNX和Libtorch)服务部署模型微调社区交流
如果在使用过程中遇到问题,可以通过以下方式寻求帮助:
在GitHub页面直接提Issue扫描README中的钉钉群二维码加入社区群相关项目
CosyVoice: 用于自然语音生成的模型,支持多语言、音色和情感控制。
代码仓库: https://github.com/FunAudioLLM/CosyVoiceModelScope空间: https://www.modelscope.cn/studios/iic/CosyVoice-300MSenseVoice.cpp: 基于GGML的纯C/C++推理实现,支持3-bit、4-bit、5-bit、8-bit量化等,无第三方依赖。
代码仓库: https://github.com/lovemefan/SenseVoice.cpp通过以上资源,相信读者可以快速入门SenseVoice项目,并根据自己的需求进行更深入的学习和应用开发。如果您对语音理解和生成感兴趣,SenseVoice无疑是一个值得关注和尝试的开源项目。






热门资讯
-

- Botpress学习资料汇总 - 开源对话式AI平台
- 1479 2024-12-16 16:31:42
-

- BibiGPT-v1: 革命性的AI音视频内容一键总结工具
- 1116 2024-12-19 05:49:31
-

- Ethora: 开源 Web3 社交平台引擎
- 1680 2025-01-06 17:56:26
-

- DouZero: 基于自我对弈深度强化学习的斗地主AI系统
- 1003 2024-12-19 02:10:32
-

- 开源数据工程项目精选:打造现代数据基础架构
- 1606 2025-01-06 16:16:54
-

- AI也能刷短视频了?!清华大学最新发布短视频理解模型,含图像文本音频多模态理解
- 1410 2024-12-31 16:07:01
-

- Diffree:最新模型实现文字指令修改图片!!这下修图变得更简单了
- 661 2024-12-31 16:27:01
-

- 北大团队最新发布全景3D技术!只需一张图片和一段话就能生成全景3D场景
- 672 2024-12-31 16:46:55
-
- React Agent 学习资料汇总 - 开源 React.js 自主 LLM 代理
- 1196 2025-01-03 17:08:43
-

- Mojo编程语言学习资料汇总 - 兼具Python语法和系统级性能的AI编程语言
- 1190 2025-01-06 14:37:19










相关常用工具
查看更多- 1 cheetah 1452
- 2 SUPIR 357
- 3 Conference-Acceptance-Rate 186
- 4 DouZero 1680
- 5 GodMode 1281
- 6 MeloTTS 1087
- 7 codefuse 319
- 8 腾讯云 AI 代码助手 1362
- 9 CodeGeeX 440