ScrapeGraphAI:开源的大语言模型爬虫,只要说出需求就会自动全网抓取想要的信息
1114 2024-12-30 00:00:00项目简介
ScrapeGraphAI 是一个基于Python的Web抓取库,使用大型语言模型和直接图逻辑来创建针对网站、文档和XML文件的抓取流程。用户只需指定想要抽取的信息,该库便能自动完成抓取任务。该项目强调易用性和高效性,支持通过命令行界面或代码实现灵活的数据抓取,并提供丰富的文档支持,帮助用户快速上手。
快速安装
这是 Scrapegraph-ai 的官方 PyPI 页面的参考信息
https://pypi.org/project/scrapegraphai/
pip install scrapegraphai你还需要安装 Playwright 用于基于 JavaScript 的网页抓取:
playwright install注意:建议在虚拟环境中安装该库,以避免与其他库冲突。
DEMO
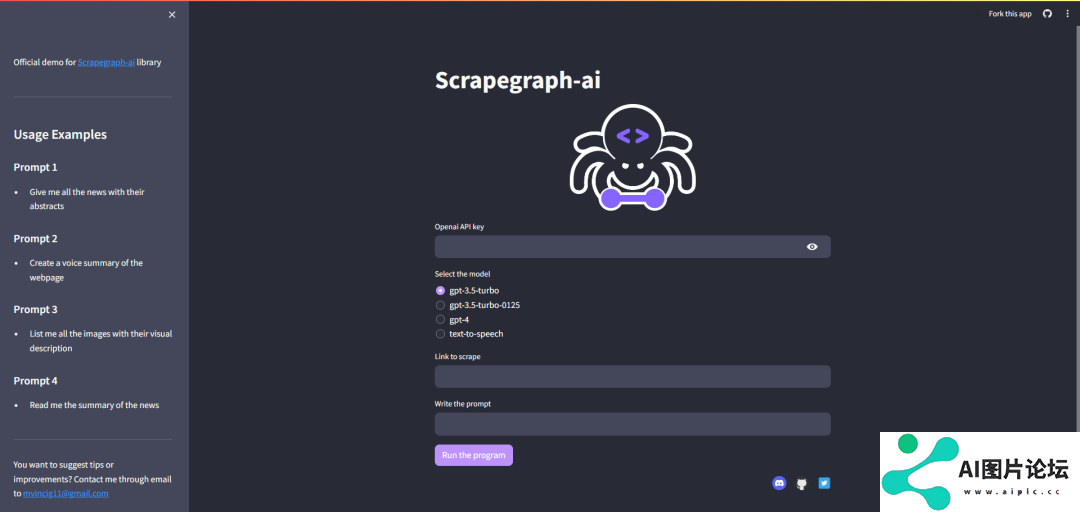
https://scrapegraph-ai-demo.streamlit.app/
使用
你可以使用 SmartScraper 类通过提示从网站中提取信息。SmartScraper 类是一个直接图实现,使用了网页抓取流程中最常见的节点。更多信息请查看文档。
https://scrapegraph-ai.readthedocs.io/en/latest/
案例 1:使用 Ollama 提取信息记得要单独下载 Ollama 的模型!
from scrapegraphai.graphs import SmartScraperGraphgraph_config = { "llm": { "model": "ollama/mistral", "temperature": 0, "format": "json", # Ollama needs the format to be specified explicitly "base_url": "http://localhost:11434" # set Ollama URL }, "embeddings": { "model": "ollama/nomic-embed-text", "base_url": "http://localhost:11434" # set Ollama URL }}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)案例 2:使用 Docker 提取信息
注意:在使用本地模型之前,记得创建 Docker 容器!
docker-compose up -ddocker exec -it ollama ollama pull stablelm-zephyr你可以使用 Ollama 上可用的模型或者你自己的模型,而不是使用 stablelm-zephyr。
from scrapegraphai.graphs import SmartScraperGraphgraph_config = { "llm": { "model": "ollama/mistral", "temperature": 0, "format": "json", # Ollama needs the format to be specified explicitly # "model_tokens": 2000, # set context length arbitrarily },}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)案例 3:使用 OpenAI 模型提取信息
from scrapegraphai.graphs import SmartScraperGraphOPENAI_API_KEY = "YOUR_API_KEY"graph_config = { "llm": { "api_key": OPENAI_API_KEY, "model": "gpt-3.5-turbo", },}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(result)案例 4:使用 Groq 提取信息
from scrapegraphai.graphs import SmartScraperGraphfrom scrapegraphai.utils import prettify_exec_infogroq_key = os.getenv("GROQ_APIKEY")graph_config = { "llm": { "model": "groq/gemma-7b-it", "api_key": groq_key, "temperature": 0 }, "embeddings": { "model": "ollama/nomic-embed-text", "temperature": 0, "base_url": "http://localhost:11434" }, "headers": { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36" }}smart_scraper_graph = SmartScraperGraph( prompt="List me all the articles", source="https://perinim.github.io/projects", config=graph_config)result = smart_scraper_graph.run()print(prettify_exec_info(result))





热门资讯
-

- Botpress学习资料汇总 - 开源对话式AI平台
- 708 2024-12-16 16:31:42
-

- BibiGPT-v1: 革命性的AI音视频内容一键总结工具
- 1958 2024-12-19 05:49:31
-

- Ethora: 开源 Web3 社交平台引擎
- 1018 2025-01-06 17:56:26
-

- DouZero: 基于自我对弈深度强化学习的斗地主AI系统
- 676 2024-12-19 02:10:32
-

- 开源数据工程项目精选:打造现代数据基础架构
- 997 2025-01-06 16:16:54
-

- AI也能刷短视频了?!清华大学最新发布短视频理解模型,含图像文本音频多模态理解
- 1742 2024-12-31 16:07:01
-

- Diffree:最新模型实现文字指令修改图片!!这下修图变得更简单了
- 1665 2024-12-31 16:27:01
-

- 北大团队最新发布全景3D技术!只需一张图片和一段话就能生成全景3D场景
- 1987 2024-12-31 16:46:55
-
- React Agent 学习资料汇总 - 开源 React.js 自主 LLM 代理
- 1826 2025-01-03 17:08:43
-

- Mojo编程语言学习资料汇总 - 兼具Python语法和系统级性能的AI编程语言
- 834 2025-01-06 14:37:19










相关常用工具
查看更多- 1 cheetah 1295
- 2 SUPIR 412
- 3 Conference-Acceptance-Rate 1700
- 4 DouZero 1010
- 5 GodMode 971
- 6 MeloTTS 898
- 7 codefuse 1836
- 8 腾讯云 AI 代码助手 1405
- 9 CodeGeeX 1115