SQLFlow: 融合SQL与AI的创新技术
1215 2024-12-19 00:00:00SQLFlow:融合SQL与AI的创新技术
SQLFlow是一个令人兴奋的开源项目,它巧妙地将SQL与人工智能技术结合在一起,为数据科学家和分析师提供了一种全新的AI开发方式。通过扩展SQL语法,SQLFlow使得用户可以直接在SQL语句中进行模型训练、预测、评估等机器学习任务,大大简化了AI应用的开发流程。
SQLFlow的核心理念
SQLFlow的核心理念是将SQL这一广泛使用的数据处理语言与先进的机器学习能力相结合。传统的AI开发往往需要数据工程师、数据科学家、业务分析师等多个角色协作,并且涉及Python、R等多种编程语言。这种分散的开发环境给工程实践带来了额外的困难。SQLFlow的目标就是通过扩展SQL语法,让具备SQL技能的工程师也能开发出先进的机器学习应用。
SQLFlow的主要特性
SQLFlow具有以下几个主要特性:
兼容多种数据库系统: SQLFlow支持MySQL、MariaDB、TiDB、Hive、MaxCompute等多种主流数据库系统。
支持多种机器学习框架: 用户可以使用TensorFlow、Keras、XGBoost等流行的机器学习框架。
扩展SQL语法: SQLFlow通过扩展SQL语法,支持模型训练、预测、评估、解释等AI任务。
生成Kubernetes工作流: SQLFlow将扩展的SQL语句编译成可在Kubernetes集群上分布式运行的Argo工作流。
易于学习和使用: 对于熟悉SQL的用户来说,学习曲线非常平缓。
SQLFlow的工作原理
SQLFlow的工作原理可以简单概括为以下几个步骤:
用户编写扩展SQL语句,包含AI任务相关的子句。SQLFlow解析该SQL语句,提取出AI任务相关的信息。根据提取的信息,SQLFlow生成相应的Python代码。将生成的Python代码编译成Argo工作流。在Kubernetes集群上执行该工作流,完成AI任务。这种方式既保留了SQL的简洁性和表达力,又赋予了它强大的AI能力。
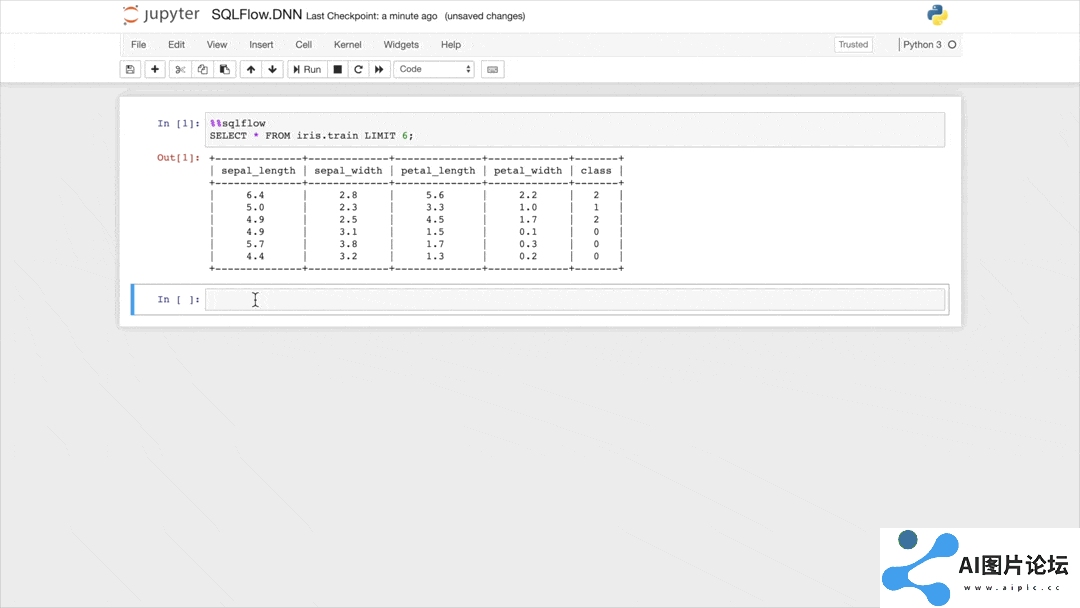
SQLFlow的应用示例
让我们通过一个简单的示例来看看SQLFlow是如何工作的。假设我们要使用著名的鸢尾花数据集来训练一个深度神经网络分类器:
SELECT *FROM iris.trainTO TRAIN DNNClassifierWITH model.n_classes = 3, model.hidden_units = [10, 20]COLUMN sepal_length, sepal_width, petal_length, petal_widthLABEL classINTO sqlflow_models.my_dnn_model;这个SQL语句做了以下几件事:
从iris.train表中选择所有数据。使用TensorFlow的DNNClassifier模型进行训练。设置模型参数:3个类别,两个隐藏层(10个和20个神经元)。指定输入特征和标签列。将训练好的模型保存到sqlflow_models.my_dnn_model。训练完成后,我们可以使用另一个SQL语句来进行预测:
SELECT *FROM iris.testTO PREDICT iris.predict.classUSING sqlflow_models.my_dnn_model;这个语句使用训练好的模型对测试数据进行预测,并将结果保存到iris.predict表的class列中。
SQLFlow的优势
SQLFlow的设计理念和实现方式带来了许多优势:
降低门槛: 让熟悉SQL的工程师也能进行AI开发,扩大了AI应用的开发人群。
简化流程: 将数据处理和模型训练集成在一起,简化了AI应用的开发流程。
提高效率: 通过自动生成代码和工作流,大大提高了开发效率。
灵活扩展: 支持多种数据库和机器学习框架,可以根据需求灵活选择。
易于集成: 生成的Argo工作流可以轻松集成到现有的Kubernetes基础设施中。
SQLFlow的未来展望
作为一个活跃的开源项目,SQLFlow正在不断发展和完善。未来,SQLFlow计划支持更多的机器学习框架和数据源,以满足不同用户的需求。同时,项目组也在积极听取社区的反馈,根据用户的实际场景和兴趣来调整开发优先级。
SQLFlow的发展roadmap包括以下几个方向:
支持更多的机器学习算法和模型。增强数据预处理和特征工程的能力。提供更丰富的模型解释和可视化工具。优化分布式训练和推理的性能。加强与各种大数据平台的集成。结语
SQLFlow作为一个创新性的项目,正在改变我们开发AI应用的方式。它不仅简化了开发流程,还为更多的工程师打开了AI应用开发的大门。随着项目的不断发展和完善,我们可以期待SQLFlow在未来为数据科学和人工智能领域带来更多的创新和突破。无论你是数据科学家、机器学习工程师,还是对AI感兴趣的SQL开发者,SQLFlow都值得你去尝试和探索。
让我们一起期待SQLFlow的未来,共同推动AI技术的普及和发展。






热门资讯
-

- Botpress学习资料汇总 - 开源对话式AI平台
- 893 2024-12-16 16:31:42
-

- BibiGPT-v1: 革命性的AI音视频内容一键总结工具
- 1266 2024-12-19 05:49:31
-

- Ethora: 开源 Web3 社交平台引擎
- 664 2025-01-06 17:56:26
-

- DouZero: 基于自我对弈深度强化学习的斗地主AI系统
- 1905 2024-12-19 02:10:32
-

- 开源数据工程项目精选:打造现代数据基础架构
- 1872 2025-01-06 16:16:54
-

- AI也能刷短视频了?!清华大学最新发布短视频理解模型,含图像文本音频多模态理解
- 1302 2024-12-31 16:07:01
-

- Diffree:最新模型实现文字指令修改图片!!这下修图变得更简单了
- 1256 2024-12-31 16:27:01
-

- 北大团队最新发布全景3D技术!只需一张图片和一段话就能生成全景3D场景
- 1566 2024-12-31 16:46:55
-
- React Agent 学习资料汇总 - 开源 React.js 自主 LLM 代理
- 1123 2025-01-03 17:08:43
-

- Mojo编程语言学习资料汇总 - 兼具Python语法和系统级性能的AI编程语言
- 1711 2025-01-06 14:37:19










相关常用工具
查看更多- 1 cheetah 960
- 2 SUPIR 198
- 3 Conference-Acceptance-Rate 1732
- 4 DouZero 736
- 5 GodMode 563
- 6 MeloTTS 1909
- 7 codefuse 1574
- 8 腾讯云 AI 代码助手 1697
- 9 CodeGeeX 253